Heterogeneous inference serving across three GPU vendors with llm-d








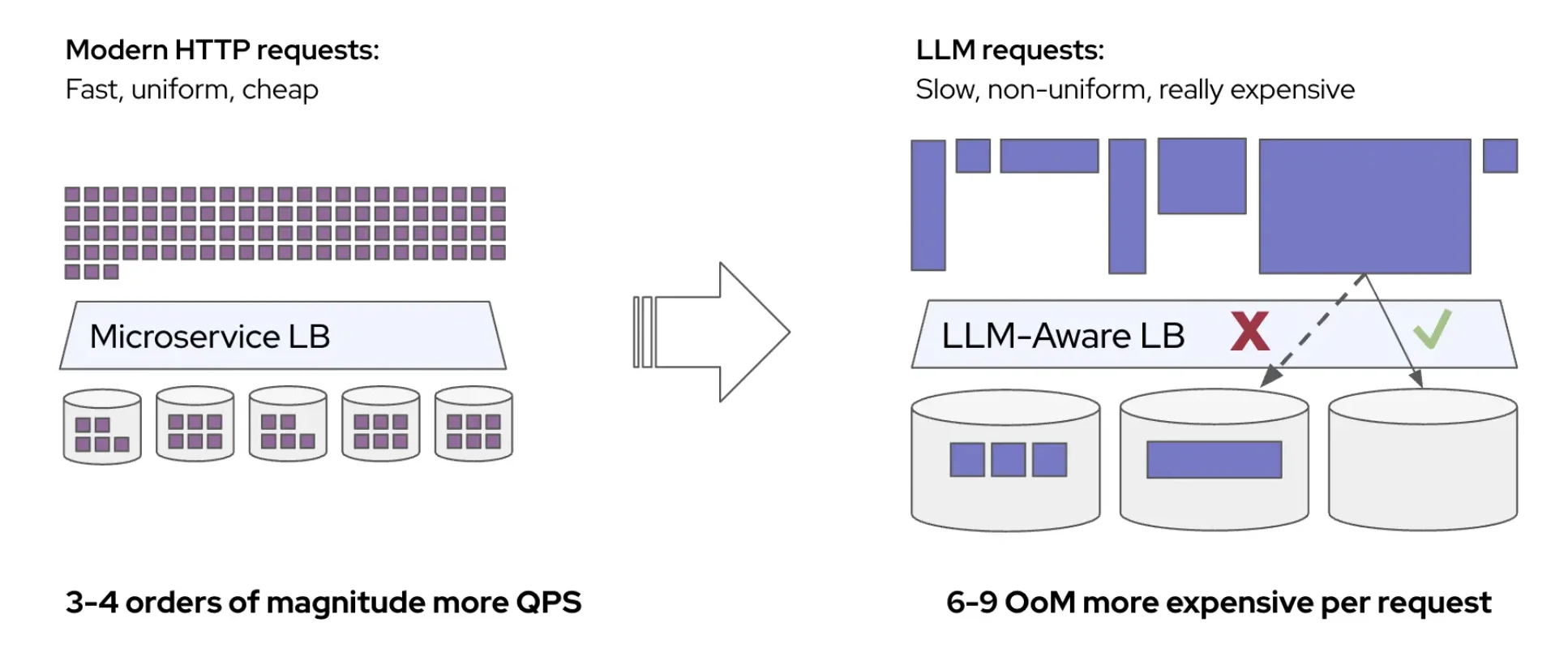
Most production inference clusters today are single-vendor because that is often the simplest way to configure and operate a cluster.
That is starting to change. Procurement cycles bring new generations alongside older ones, supply planning spans multiple accelerator options, and cost/performance profiles differ by workload. Real production fleets are accumulating heterogeneity whether or not the architecture planned for it.
This is an opportunity to unlock real value: different accelerator classes can be matched to workload requirements, stranded capacity gets reclaimed, and operators gain more flexibility in capacity planning. The case is stronger still for sovereign and on-premise deployments, where data residency, regulatory alignment, and the long-term economics of high-volume inference make local fleet optimization especially important.
Making that work in practice is a non-trivial systems problem. Each accelerator stack brings its own optimized drivers, firmware, container images, runtime settings, and attention kernels. A coherent serving layer needs to preserve those platform-specific optimizations while still giving operators one control plane for routing, observability, and policy.